Style Sampler
Layout Style
Patterns for Boxed Mode






Backgrounds for Boxed Mode
Search News Posts
General Inquiries 1-888-555-5555
•
Support 1-888-555-5555

Variant Analysis
Today, the development of computer technologies has affected the studies in many areas. Advances in molecular biology and computer technologies have revealed the science of bioinformatics. Rapid developments in the field of bioinformatics have contributed greatly to the solution of many problems waiting to be solved in this field.
The classification of DNA microarray gene expressions is one of these problems. DNA microarray studies are a technology used in the field of bioinformatics. DNA microarray data analysis plays a very effective role in the diagnosis of diseases related to genes such as cancer. By determining gene expressions depending on the type of disease, it can be determined with great success rate whether any individual possesses the diseased gene.
The use of high-performance classification techniques on microarray gene expressions is of great importance to determine whether an individual is healthy.
There are many methods for classifying DNA microarrays. Support Vector Machines, Naive Bayes, k-Nearest Neighbour, Decision Trees, such as many statistical methods are widely used. However, when these methods are used alone, they do not always give high success rates in classifying microarray data. Therefore, the use of artificial intelligence-based methods to achieve high success rates in the classification of microarray data is seen in the studies.
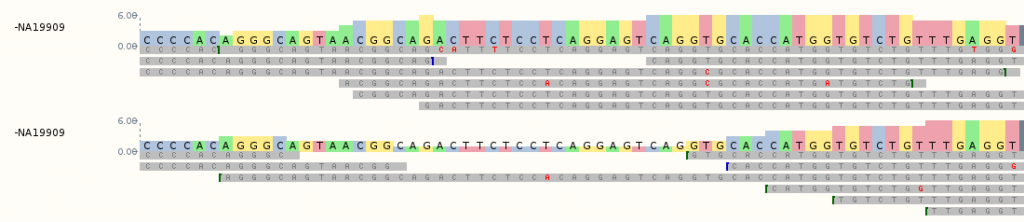
A likely workflow in human genetic variation studies is the analysis and identification of variants associated with a specific trait or population. Bioinformatics is key to each stage of this process and is essential for handling genome-scale data. It also provides us with a standardised framework to describe variants.
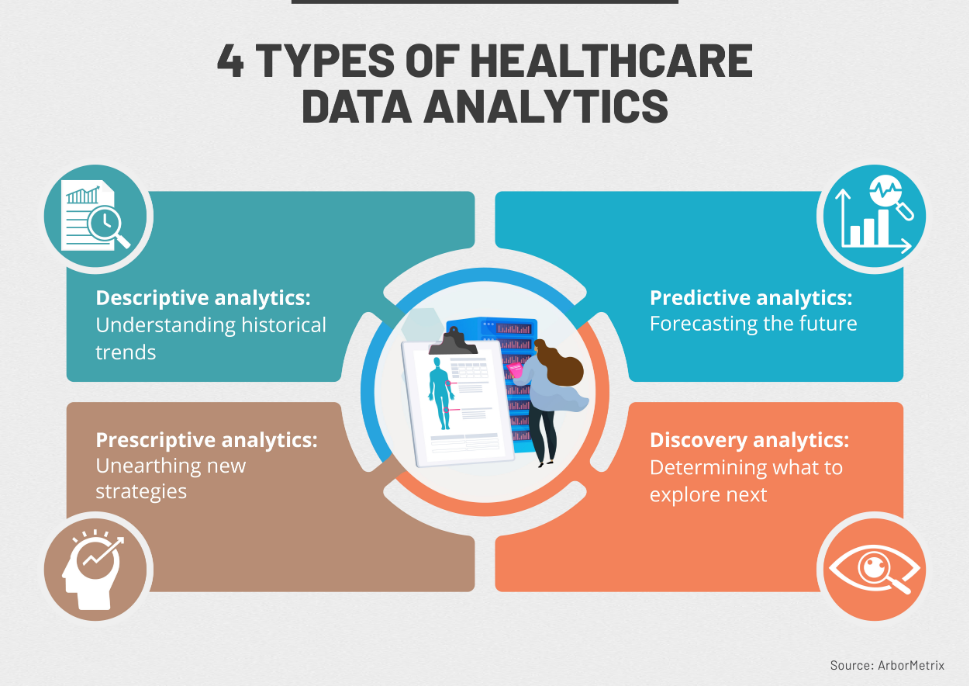
The goal of quality improvement in healthcare settings is to treat patients safely and effectively while minimizing the trauma associated with their treatment. To achieve this goal, healthcare providers collect and analyze patient data, increasingly in real time, to gain a clearer understanding of today’s complex healthcare environments; to develop and apply a systematic approach to improve patient outcomes; and to continuously develop, test, and implement enhancements to healthcare processes.
By analyzing patient data, healthcare providers can lower readmission rates, reduce errors, and better identify at-risk populations. The types of patient data used in these analyses include blood sugar level, temperature, blood test results, and the patient’s own wishes for care. The primary factors that influence the quality of care patients receive are:
TARİH
CAC
DAX
DJI
SP
FTSE
NIKKEI
NASDAQ
VIX
Clinical studies are conducted in a controlled environment and their outcomes are evaluated for statistical purposes. Machine Learning methods are ideal for deriving answers from data material. They cannot only provide answers to questions but also discover patterns that have yet not been recognized.
We can analyze your clinical studies retrospectively (secondary analysis) and/or gather any information prospectively. In doing so we can develop new analytical procedures, such as for the study of chronic diseases related to the immune system.
A significant amount of information vitally important to routine medical procedures exists in the form of text documents. These documents can be wide ranging and can include specialized medical literature and study outcome publications as well as physician’s letters and medical reports.
We offer Text Mining solutions based on "Natural Language Understanding". It involves extracting the essential information from all of the relevant documents and making it available in a structured format.
The healthcare sector can benefit enormously from digitalization and the opportunities it creates for increased efficiency, quality and new ways of working.
We help you identify and unlock this potential. We also support you with the design and targeted implementation of a made-to-measure digitalization strategy.
Working together we can determine which procedures need to be digitalized and what specific application scenarios might look like.
As in every period, in the field of medicine, which is the most important research area of our day, the data of the patients are continuously recorded. While the recorded data sometimes seem to be insignificant alone, it is possible to obtain important information that is hidden when it is analyzed together with other data. Thanks to the valuable information obtained, it helps the development of the health sector and the correct diagnosis of the doctors.
Text is one of the most essential categories in EHRs since it contains important information on the patient’s health status, like tests results, diagnosis, treatments, etc. Besides that, other facultative data, such as the medical history of the family, allergies, are also collected and recorded in order to aid in clinical decisions and to avoid diseases or misapplication of treatments.
Medical images represent the procedures used to image the inside(interior) of a patient’s body for clinical analysis. It is generated commonly by using X-rays, Magnetic Resonance Imaging (MRI), Microscopy Image, Optical Coherence Tomography (OCT), or Position Emission Tomography (PET).
Electronic health records (EHR) is an advanced and electronic version of the health information system that provides documentation on illnesses, previous consultations, and examination results.
If we ask the question, What are the challenges in the healthcare industry? We can give these answers. The challenges for its implementation in the healthcare industry are:
The availability of data is among the most frequent problems that businesses have with machine learning. For businesses to use machine learning, raw data must be accessible. Large amounts of data are required to develop machine learning algorithms. A few hundred bits of data are insufficient to train systems properly and use machine learning.
Data collection is not the only issue, though. Additionally, you must model and refine the data to conform to the chosen algorithms.
One of the problems with machine learning that is regularly encountered is data security. Security is a crucial issue that must be addressed when a corporation has retrieved data. To use machine learning accurately and effectively, it is crucial to distinguish between sensitive and non-sensitive data. Companies must store sensitive data by encrypting and putting it on other servers or in a location with complete security. Reliable team members can be given access to less sensitive information.
anaplatform Big Data offers appropriate technology and solutions for all sectors. Until today, Software Houses, GSM, Insurance, E-Commerce, Bank - TSM, Automobile, Education, Payment Systems, Robot Industry - guided missile etc. and served in many other fields.




